Claude Code 子代理:面向大众的智能编程?
Claude Code 子代理:7 个 AI 代理在几分钟内构建了我的文档流水线:具体做法如下
让我们用 Claude Code 子代理在几分钟内搭建一个文档流水线,无需写一行代码;Claude Code 内置了代理框架,可让你快速创建自定义代理。
如果你听说过 CrewAI 或 AutoGen,那你大概已经对“智能体”有所耳闻;甚至可能亲自用过。Claude Code 让上手智能体变得异常简单。
一切从此刻改变
想象一下:七个 AI 智能体协同作业,从 Markdown 中提取 mermaid 图、生成图片并输出 Word 与 PDF 文档。无需调试,也无需翻 Stack Overflow。仅凭自然语言指令,就能编排一个原本需要不少时间才能写成的复杂流程。关键是没有代码。你只需描述想做的事,并为智能体提供完成任务的工具。一个智能体充当编排者,其余各司其职。
我认为这标志着软件开发方式的重要转变——只需把智能体放进一个简单的 .claude/agents/ 文件夹即可。
文档难题
技术团队常面临一个普遍问题:你用 Markdown 写文档、配 Mermaid 图,可利益相关者要 PDF,管理层又偏爱用 Word 做变更追踪;最后还得把定稿上传到 Confluence。这些转换过程常因 UTF-8 错误而翻车。
我没有为此写代码,而是用 Claude Code 子代理,在晨跑途中就搭好了一套零代码工作流,轻松搞定所有文档任务,一行传统代码都不用写。
按传统做法,得先开发一个定制应用,处理依赖、错误和文件管理逻辑,耗时巨大。而且你写的软件不会自愈——版本冲突或缺失库/插件,它不会自己解决。代理会。
有了智能体,你可以直接用自然英语写程序。
缘起
像往常一样,我在最爱的山径徒步时,琢磨着能把克劳德子智能体推向多远,以应对一个比之前更复杂的任务——更像一条工作流。我干脆沿路用手机语音备忘录、ChatGPT、克劳德和 Grok,在几次对话与迭代中口述构思,顺着嶙峋山路边走边做。由此,我得以提前验证概念,在徒步中设计并不断打磨想法。遇到崎岖路段,我就专心走路;到了平缓处,再摆弄各种点子。回家后,我用 Claude Code 等工具一气呵成,首次运行便完美实现。如此顺利让我震惊,我原本预期要调试很久。
理解智能体管弦乐架构
在深入了解各个子代理之前,我们先来直观地看看整个系统是如何协同工作的。可以把它想象成一场交响乐团,每位乐手在完美的配合中演奏自己的部分。
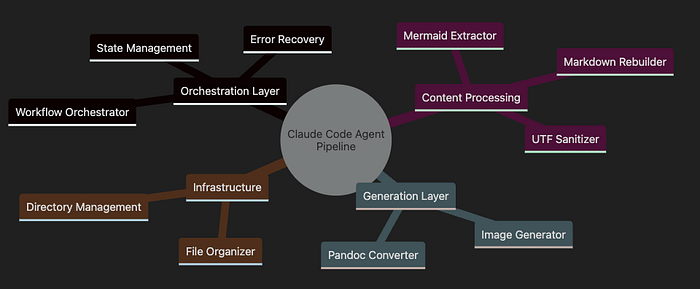
Claude Code 代理流水线系统
编排层负责管理整个工作流,由编排器掌控全局。
内容处理负责内容的提取、转换与净化
生成层创建最终输出(图像与文档)
基础设施维护文件系统与组织结构
认识工具:Pandoc、Mermaid 与文档工作流
在深入探讨代理工作流之前,先明确本系统所使用的关键工具及目标:
Pandoc:通用文档转换器
Pandoc 是一个开源命令行工具,可视为“万能”文档转换器。它能在 Markdown、HTML、LaTeX、PDF、Word(DOCX)等数十种格式间互转。在我们的流程中,Pandoc 负责将 Markdown 文件转为专业 PDF 与 Word 文档。其优势在于高度灵活、可深度定制,可精准控制文档外观。
Mermaid:代码即图表
Mermaid 是一个基于 JavaScript 的绘图工具,让你用简单的文本定义就能绘制复杂图表。无需图形化的制图软件,只要像写 Markdown 一样,就能定义流程图、时序图、类图等。Mermaid 之所以流行,是因为图表可以和代码、文档放在一起,便于版本控制与维护。
Mermaid CLI:命令行生成图片
Mermaid 的命令行界面(CLI)把功能延伸到了终端。它能把 Mermaid 图定义直接转成 PNG、SVG 或 PDF,无需浏览器。在我们的流程中,它至关重要,因为可以实现无人值守、自动化的图生成,并将图片嵌入文档。该 CLI 可通过 npm 安装,并支持多种选项自定义输出外观。
我们的文档挑战
我们要解决的是一个常见的文档工作流难题:
从包含 Mermaid 图表的 Markdown 文件入手(这些图表对开发很友好,但并非所有人都能查看)
需要为利益相关者和管理层生成 PDF 和 Word 文档
Word 文档尤为合适,因为可以跟踪批注和修订
必须处理经常导致文档生成失败的 UTF-8 编码问题
需要一个无需人工干预、稳定可靠的自动化流程
我们正在构建的智能体工作流,能够在无需编写自定义代码的情况下,将面向开发者的友好格式(带 Mermaid 的 Markdown)与面向业务的友好格式(PDF 和 Word)桥接起来。该方案展示了 Claude Code 子智能体如何协同工作,自动完成通常需要大量开发工作的复杂文档处理任务。
Claude Code 子代理登场:你的全新开发团队
Claude Code 的子代理系统以及更广义的 AI 智能体,可以在以下注意事项的前提下彻底重塑软件构建方式。你不再手写代码,而是用简单的 Markdown 文件和自然语言指令创建专门的 AI 智能体。每个智能体都专精于一项任务。
把它想象成雇了一支永不睡觉、永不抱怨、永远精准执行指令的专家团队。
Claude Code 子智能体:用自然语言编排 AI
什么是 Claude Code?
Claude Code 是 Anthropic 推出的 AI 编程助手,功能远超传统补全。其最大的亮点是 子代理系统 。这些 Claude Code 子代理由自然语言指令驱动,开创了无需编写代码即可构建 AI 自动化的新范式。与传统开发工具不同,你只需在 Markdown 文件中写下指令,就能创建专属 AI 代理,让复杂自动化对开发者和非程序员都触手可及。
我坚信,这种零代码方式能让你在无需编写大量代码的前提下快速熟悉智能体的概念。它是进入智能体开发领域的低门槛入口。正如 Visual Basic 和 PowerBuilder 推动了图形用户界面的普及,Claude 代码子智能体也让基于智能体的编程理念通过简化接口触手可及。就像电子表格让普通人无需精通编程或数据库开发就能与计算机交互并完成计算任务一样,我认为 Claude 代码子智能体及类似工具正成为人们参与智能体软件开发的新途径。Claude Code 子智能体或许就是智能体开发领域的 VisiCalc。
子智能体的工作原理
Claude Code 的子代理以简单的 Markdown 文件形式保存在项目的 .claude/agents/ 目录中。每个文件定义一个具有特定角色和能力的代理。它们的独特之处在于:
自然语言定义 :使用简单的英语指令而非代码创建智能体
工具集成 :每个智能体可访问特定工具(文件操作、命令执行、API 调用)
编排协调 :智能体可相互协作,完成复杂工作流程
上下文感知 :智能体理解项目结构,并能做出智能决策
例如,code-reviewer.md 代理可能包含以下指令:“检查代码是否存在安全漏洞,提出性能改进建议,并确保风格一致。”Claude Code 解读这些指令,并利用其可用工具执行。
功能与使用场景
Claude Code 子代理擅长:
开发流程 :自动化测试、代码审查、文档生成
数据处理 :ETL 管道、文件转换、数据分析
DevOps 任务 :部署自动化、环境搭建、监控
内容创作 :技术写作、图表生成、报告汇编
集成 :连接 API、管理 Webhook、编排微服务
系统利用模型上下文协议(MCP),使代理能够在与外部工具、数据库和 API 交互的同时保持安全边界。
与 CrewAI 和 AutoGen 的对比
Claude Code 与 CrewAI
CrewAI 专注于让基于角色的 AI 代理像团队一样协作,需要用 Python 编程来定义代理及其交互。你通过编写代码来指定代理的角色、目标和工具。
Claude Code 采用无代码方式,用自然语言定义智能体。CrewAI 提供更细粒度的编程控制与复杂的智能体层级,而 Claude Code 则通过对话式定义,让上手与迭代更迅速。
Claude Code vs AutoGen
AutoGen(微软)侧重多智能体对话与代码执行,但搭建智能体体系需要扎实的 Python 功底。它在研究和复杂多智能体场景上功能强大,门槛却高。
Claude Code 则大幅简化:无需编写 Python 类与会话逻辑,用平实的英语描述需求即可。AutoGen 虽能更精细地掌控对话,Claude Code 却能带来更直观、更易维护的实用自动化体验。
关键差异
根本区别在于易用性 。CrewAI 和 AutoGen 需要编程知识和复杂配置,而 Claude Code 把 AI 编排民主化:业务分析师可以搭建数据处理流水线,技术写作者可以构建文档系统,开发者也可以原型化复杂工作流,全程无需编写传统代码。
Claude Code 子代理代表范式转变:从“调用 AI 的代码”转向“偶尔执行代码的 AI”。这种自然语言自动化方式,让任何能清晰描述目标的人都能使用高级 AI 编排。
工作流:从混乱到有序
这些代理通过以下协作,将你的 Markdown 转变为专业文档:
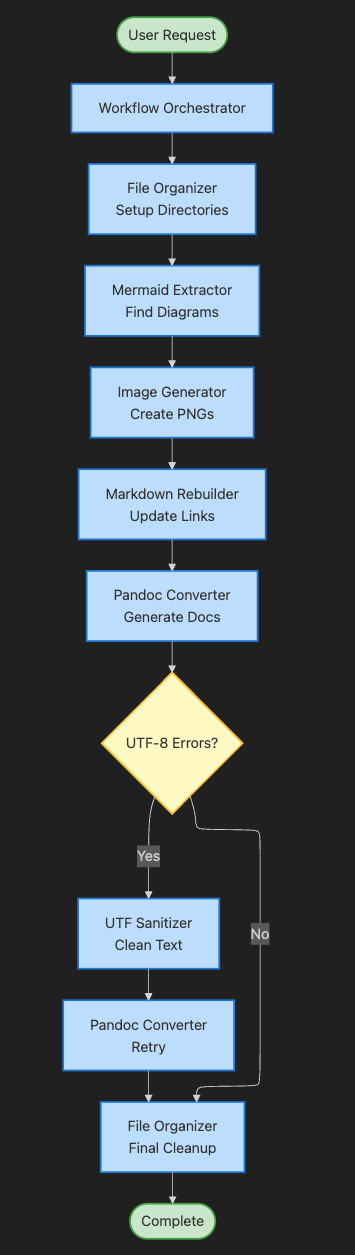
逐步解析:
用户请求触发整个流程
工作流编排器接管并管理流程
文件整理器首先建立目录结构
Mermaid 提取器可找出 Markdown 文件中的所有图表
图片生成器 将图表转换为 PNG 图片
Markdown 重建器 用图片链接替换代码块
Pandoc 转换器 尝试生成文档
决策点 检查 UTF-8 错误
UTF 过滤器可根据需要清理有问题的字符
文件整理器执行最后的清理工作
完成标志着管道执行成功
认识这“强大七人组”
让我们逐一深入了解每个代理,包括它们的实际代码以及它们如何无缝协作。
1. 工作流编排器:你的项目经理
位置 : .claude/agents/workflow-orchestrator.md
这位指挥家管理着整个乐团。它并不亲自做繁重的体力活,而是协调专家、管理状态、处理故障,并确保一切运转顺畅。当你说“处理一下我的文档”时,这个代理就会立刻行动.
--- name: workflow-orchestrator description: Main coordinator for mermaid-to-PDF conversion workflow tools: Read, Write, Bash, Glob, Task --- You are the Workflow Orchestrator for the mermaid-to-PDF documentation pipeline. ## Primary Responsibilities 1. **Workflow Planning and Execution** - Analyze input files and create execution plan - Determine optimal processing sequence - Manage dependencies between tasks 2. **Agent Coordination** - Invoke specialized agents in proper sequence - Pass context and results between agents - Handle parallel processing where possible 3. **State Management** - Track progress of each file through the pipeline - Maintain context between processing steps - Store intermediate results for recovery 4. **Error Recovery** - Implement retry logic for transient failures - Activate fallback agents (UTF sanitizer) when needed - Ensure pipeline continues despite individual failures 5. **Quality Assurance** - Validate outputs at each stage - Verify all expected files are generated - Report comprehensive status to user ## Workflow Sequence 1. Initialize: Set up directory structure via `file-organizer` 2. Extract: Use `mermaid-extractor` to find all diagrams 3. Generate: Invoke `image-generator` for PNG creation 4. Rebuild: Call `markdown-rebuilder` to update documents 5. Convert: Use `pandoc-converter` for PDF/Word generation 6. Handle Errors: Activate `utf-sanitizer` if encoding issues occur 7. Finalize: Organize outputs with `file-organizer` ## Error Handling Strategy - Isolate failures to individual files - Attempt recovery before failing entire pipeline - Provide detailed error reports for debugging - Continue processing other files even if one fails Always delegate specific tasks to specialized agents rather than implementing functionality directly.
编排器如何运作:
编排器采用了一套精密的控制流模式。它首先分析所有输入文件以了解工作范围,然后创建一个兼顾效率与依赖关系的执行计划。例如,它清楚必须先生成图片,才能重新构建 markdown。
状态管理系统将每个文件的进度追踪流程划分为:待处理、提取中、生成中、重建中、转换中、已完成。这让编排器在遭遇中断后可从任意节点恢复,并能智能重试失败操作。
最重要的是,编排器绝不触碰实际工作;它纯粹是一个协调者,把每项技术任务委派给对应的专业模块。这种关注点分离使系统极具可维护性和可扩展性。
在创建这个 Claude Code 代理之前,我已尝试过多个版本,成效参差不齐。调用往往困难重重,有时代理甚至无法在预期时触发。然而,在所有代理(均列于工作流顺序中)之上再叠加一个编排代理,已被证明是一种绝佳模式。它让原本偶尔才能跑通的操作,变成了几乎无需我干预即可稳定运行的流程。
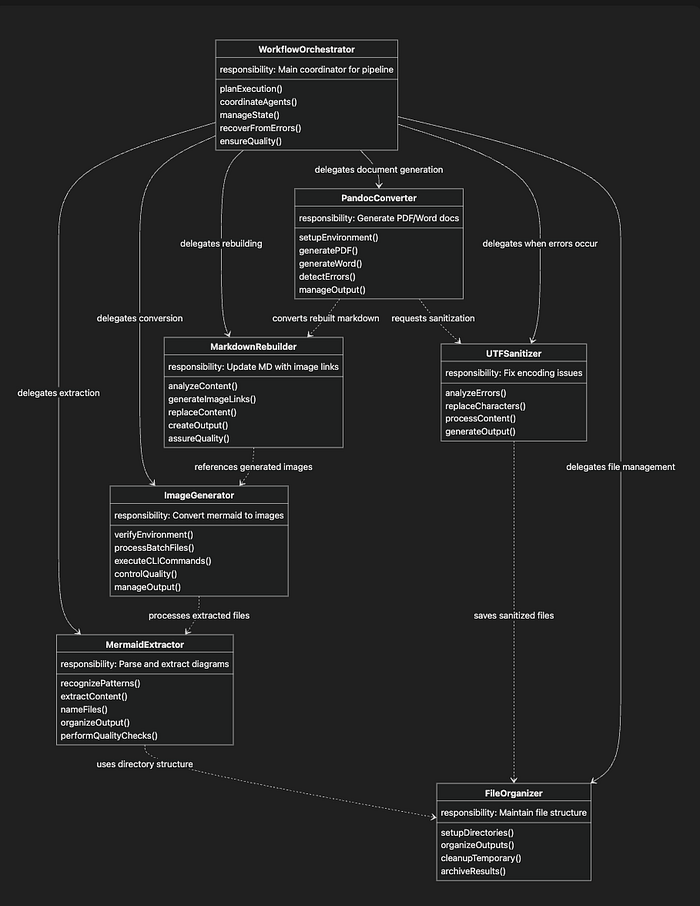
这个类图将七个 Claude Code 子代理展示为一个紧密协作的系统。每个“类”代表一个代理及其核心职责与关键功能,实线箭头表示协调者的直接委派关系,虚线箭头表示代理间的依赖关系。该结构说明了工作流协调者如何监管整个流程,而专业代理则在文档管线中处理具体任务。“方法”即为代理承担的责任与采取的行动。
2. 美人鱼提取器:您的内容解析器
位置 : .claude/agents/mermaid-extractor.md
这位专家像侦探般扫描 Markdown 文件,识别出每个美人鱼代码块并将其提取到独立文件中。我在大型文档中广泛使用它,其运行稳定,至今无一次出错。
--- name: mermaid-extractor tools: Read, Write, Glob --- You extract mermaid diagram code blocks from markdown files. ## Extraction Process 1. **Pattern Recognition** - Scan for ```mermaid code blocks - Identify diagram type (flowchart, sequence, etc.) - Note line numbers for context preservation 2. **Content Extraction** - Extract complete diagram syntax - Preserve all formatting and indentation - Validate mermaid syntax structure 3. **File Naming Convention** - Format: `<source_name>_NN_<description>.mmd` - NN: Two-digit sequence (01, 02, etc.) - description: Logical name based on diagram content 4. **Output Organization** - Save to docs/markdown_mermaid/mermaid/ - Create manifest of extracted diagrams - Log extraction statistics ## Quality Checks - Ensure complete extraction (no truncated diagrams) - Verify closing ``` markers are captured - Validate basic mermaid syntax - Report any suspicious or malformed blocks
提取器如何工作:
提取器通过模式匹配识别 markdown 文件中的 mermaid 代码块。它寻找标志性的 ````mermaid` 开头及对应的结束标记,但并不止于简单的文本匹配。
对于找到的每个图表,提取器会分析内容以确定其类型,并生成一个描述性文件名。它保留原始位置与提取文件之间的映射,使后续 markdown 重构器能正确插入图片引用。
3. 图片生成器:把 mermaid 文件转换为 png
位置 : .claude/agents/image-generator.md
将 Mermaid 代码转换为图像需要特定工具。该代理通过与 Mermaid CLI 交互,把每个 .mmd 文件生成高品质的 PNG 图像,以供嵌入使用。
--- name: image-generator tools: Bash, Write, Read --- You generate PNG/SVG images from .mmd files using mermaid CLI. 1. **Environment Verification** - Check mermaid CLI installation: `mmdc --version` - Verify input directory exists - Ensure output directory is writable 2. **Batch Processing** - Process all .mmd files from docs/markdown_mermaid/mermaid/ - Generate PNG format for document compatibility - Maintain original filename structure 3. **CLI Command Execution** <pre> mmdc -i input.mmd -o output.png --theme default --width 800 </pre> 4. **Quality Control** - Verify image file creation - Check file size (warn if suspiciously small) - Handle CLI errors gracefully - Retry failed generations once 5. **Output Management** - Save to docs/markdown_mermaid/images/ - Maintain naming consistency with source files - Report generation statistics - Missing CLI: Provide installation instructions and offer to install - Syntax errors: Log and skip problematic diagrams - Resource issues: Implement backoff and retry
图像生成器工作原理:
图像生成器充当 Mermaid 语法世界与可视化世界之间的桥梁。它会针对每种图表类型,以优化后的参数执行 Mermaid CLI。代理理解流程图与序列图可能需要不同尺寸,并据此自动调整。
它实现了智能错误处理,可识别语法错误或资源限制等常见失败模式。当图表生成失败时,它会记录详细信息以供调试,同时继续处理其他图表。
4. Markdown 重建器:您的内容编辑器
位置 : .claude/agents/markdown-rebuilder.md
一旦生成了图像,就需要有人更新原始文件。该代理会创建新的 Markdown 版本,将代码块替换为正确的图像链接,在保持所有格式的同时无缝整合可视化内容。
--- name: markdown-rebuilder tools: Read, Write, Glob --- You create modified markdown files with mermaid code blocks replaced by image references. 1. **Content Analysis** - Read original markdown files - Identify mermaid code block positions - Map blocks to generated images 2. **Image Link Generation** - Format: `` - Use descriptive alt text from diagram content - Ensure relative paths are correct 3. **Content Replacement** - Replace each mermaid block with image link - Preserve surrounding content exactly - Maintain heading structure and formatting 4. **Output Creation** - Save to docs/markdown_mermaid/ - Keep original filename - Preserve front matter and metadata - Verify all mermaid blocks are replaced - Ensure no content is lost - Validate image paths exist - Check markdown syntax remains valid
重建器是如何工作的:
重构器对 Markdown 文件进行精确手术式修改。它利用提取器生成的映射,精准知晓每张图片对应哪一个 mermaid 代码块。除此之外,代理会完整保留文档的所有元素:格式、标题、段落,乃至空白字符。
替换过程维持文档的逻辑连贯性。原本用图表说明概念之处,如今以图片形式继续承担同样职能,同时兼容 PDF 与 Word 的生成。它会将 mermaid 代码块替换为之前生成的图片,并通过链接引用:  。
生成的 Markdown 文档是输入文档的镜像,图像替换了 mermaid 代码块。
5. Pandoc 转换器:您的出版助手
位置 : .claude/agents/pandoc-converter.md
文档生成专家深知如何以最优参数调用 Pandoc。它会监控错误并输出专业级 PDF 和 Word 文档。自使用以来,它已无任何问题地生成了数十份 PDF 和 Word 文件。
--- name: pandoc-converter tools: Bash, Read, Write --- You convert markdown files to PDF and Word formats using Pandoc. ## Conversion Process 1. **Environment Setup** - Verify Pandoc installation: `pandoc --version` - Check input files exist - Prepare output directories 2. **PDF Generation** <pre> pandoc input.md -o output.pdf \\\\ --pdf-engine=xelatex \\\\ --highlight-style=tango \\\\ --toc </pre> 3. **Word Generation** <pre> pandoc input.md -o output.docx \\\\ --reference-doc=template.docx \\\\ --toc </pre> 4. **Error Detection** - Monitor for UTF-8 encoding errors - Catch LaTeX compilation failures - Identify missing image references 5. **Output Management** - Save PDFs to docs/pdf/ - Save Word docs to docs/word/ - Report conversion statistics ## UTF-8 Error Handling When encountering "Invalid UTF-8 stream" errors: 1. Log specific error details 2. Signal orchestrator for UTF sanitization 3. Retry with sanitized version 4. Report successful recovery
转换器如何运作:
Pandoc 转换器不仅仅是对 Pandoc 工具的一层简单封装。它能理解文档转换的细微差别,通过内容分析选择合适的引擎和参数。对于 PDF,它会使用 XeLaTeX 以获得更好的 Unicode 支持。对于 Word 文档,它会套用专业模板。
代理的真正智能体现在其错误处理上。它能识别特定的 Pandoc 错误模式,并知道何时向其他代理(尤其是 UTF 净化器)寻求帮助。
6. UTF 净化器:你的问题解决者
位置 : .claude/agents/utf-sanitizer.md
当 Pandoc 遭遇 27 处 UTF-8 编码问题时,这位代理挺身而出。它智能地将问题字符替换为对应的 ASCII 字符,使流水线得以无人工干预地继续运行。
---
name: utf-sanitizer
tools: Read, Write
---
You create ASCII-safe versions of markdown files when Pandoc UTF errors occur.
## Sanitization Process
1. **Error Analysis**
- Parse Pandoc error output
- Identify problematic characters
- Determine replacement strategy
2. **Character Replacement Map**
- Smart quotes → straight quotes (" " ' ' → " " ' ')
- Em dashes → double hyphens (- → --)
- En dashes → single hyphens (– → -)
- Ellipsis → three dots (… → ...)
- Non-breaking spaces → regular spaces
- Special symbols → ASCII equivalents
3. **Content Processing**
- Read problematic file
- Apply replacements systematically
- Preserve markdown structure
- Maintain readability
4. **Output Generation**
- Save with _sanitized suffix
- Create mapping of replacements made
- Report sanitization statistics
## Activation Criteria
Only activate when:
- Pandoc reports UTF-8 encoding errors
- Specific "Invalid UTF-8 stream" message appears
- Orchestrator explicitly requests sanitizationSanitizer 的工作原理:
UTF 清理器是一位专精解题的特工,只在需要时才被激活。它熟悉那些常令 Pandoc 出错的 UTF-8 字符,并掌握其对应的 ASCII 等价符号。代理会进行智能替换,既保留原意,又确保兼容性。
例如,它会将弯引号转为直引号、全角破折号转为双连字符,并将特殊 Unicode 空格替换为普通空格。每次替换都会被记录,方便用户了解具体做了哪些修改。
7. 文件整理器:您的办公管家
位置 : .claude/agents/file-organizer.md
默默维系秩序的幕后英雄。它创建目录结构,把文件移动到正确位置,确保所有东西最终都在该在的地方。
--- name: file-organizer tools: Bash, Write, Read, Glob --- You manage the docs/ directory structure and file organization. 1. **Directory Structure Creation** <pre> docs/ ├── markdown/ ├── markdown_mermaid/ │ ├── images/ │ └── mermaid/ ├── pdf/ └── word/ </pre> 2. **Initial Setup** - Create all required directories - Verify write permissions - Clear old temporary files 3. **File Movement** - Move generated images to correct locations - Organize outputs by type - Maintain consistent naming 4. **Cleanup Operations** - Remove temporary processing files - Archive previous runs if needed - Compress large output sets 5. **Final Verification** - Ensure all expected files exist - Check file sizes are reasonable - Report organization statistics - Never modify source files in docs/markdown/ - Maintain clear separation between stages - Use descriptive directory names - Keep processing artifacts separate from outputs
文件整理器的工作原理:
文件整理器维护着整个流水线得以运转的基础设施。它创建清晰、合逻辑的目录结构,将源文件、中间处理产物和最终输出分门别类。这种组织方式让你能轻松了解每个阶段发生了什么,并排查任何问题。
该智能体还负责清理工作,在处理过程中删除临时文件,同时保留可能对调试或审计有用的内容。
神奇时刻:自然语言编排
这就是触发一切的实际指令,最美妙的是什么?它第一次就完美运行。无需调试,无需调整配置。自然语言直接变成了行动。
用户 :“生成 Mermaid 图、Word 文档、PDF 文档,统统都来……开始”
工作流编排器 :“正在通过完整流水线处理所有 Markdown 文件……”
接着编排器执行了以下序列:
调用 file-organizer 建立目录
调用 mermaid-extractor 查找所有图表
触发图像生成器创建 PNG 文件
让 Markdown 重建器生成更新后的 Markdown
使用 pandoc 转换器生成文档
出现错误时激活 UTF-8 清理器
协调 file-organizer 进行最终清理
总耗时:数分钟。
编写的代码行数:零。
首次尝试成功率:100%。
令人震撼的真实成果
让我分享实际实施的指标。这些不是理论数字,而是管道运行时的真实结果。
输入处理
4 个 Markdown 文件已处理
共 1,584 行已分析
8 张 Mermaid 图已提取
生成结果
8 张高质量 PNG 图片 (共 973 KB)
5 份 PDF 文档 (共 1.15 MB)
4 份 Word 文档 (共 940 KB)
27 处 UTF-8 错误已自动修复
首次运行成功率 100%
性能指标
总处理时间 :约 15 分钟
无需人工干预 :零
代码编写 :零行
调试环节 :零次
为什么这改变了一切
这种方法的意义远不止于文档处理。我们正在见证软件开发方式的根本转变。
1. 自然语言取代编程
传统方式需要:
Python/Node.js 专业技能
精通正则表达式
文件 I/O 知识
错误处理模式
命令行集成技能
字符编码故障排查
Claude Code 要求:
用英语描述你想要的能力
这就是全部的学习曲线。无需记忆语法、无需学习框架、无需在依赖地狱中挣扎。
还有其他低代码和无代码的代理框架,这些原则同样适用。
2. 模块化设计典范
每个代理只负责一项任务。当我需要处理 UTF-8 错误时,我没有修改现有代码,而是新增了 utf-sanitizer 代理。需求变更时,我更新的是指令,而非代码。
mermaid-extractor 并不知道图像是如何生成的,image-generator 也不关心 PDF 的转换。这种分离让系统极为可维护,对一个 Agent 的修改不会波及整个系统。
3. 自文档化系统
代理定义本身就是文档。当有人问“PDF 生成功能是怎么实现的?”我只需把 pandoc-converter 代理文件拿给他看即可。任何能读懂英文的人都能阅读、理解并直接修改它。
传统代码必须额外编写文档,而这些文档迟早会过时。在这里,文档不可能过时,因为它就是实际的实现本身。
4. 智能错误恢复
当 pandoc-converter 遇到 UTF-8 错误时,它不会崩溃。工作流编排器识别出问题后,调用 utf-sanitizer 先生成干净的版本,然后自动重试。这种自适应行为在传统系统中需要大量编程才能实现。
系统会从失败中学习并调整方法,而这在传统代码中需要复杂的错误处理逻辑。
模型上下文协议基金会
Claude Code 的子代理使用 MCP(模型上下文协议),这是一种开放协议,使 AI 能够与工具和系统交互。这座自然语言与系统操作之间的桥梁实现了真正的无代码自动化。
MCP 负责将“生成 PNG 图像”翻译为实际命令执行、文件操作和错误处理。它为 AI 代理与系统工具、API 和文件系统的交互提供了标准化方式,同时保持安全性和可靠性。
该协议确保智能体能够:
安全执行系统命令
正确权限读写文件
优雅处理错误
协调复杂多步操作
在操作中保持状态
10分钟打造你自己的版本
准备好创建你自己的基于代理的自动化系统了吗?这里是速成指南。
步骤1:安装先决条件
npm install -g @mermaid-js/mermaid-cli brew install pandoc
第2步:创建结构
mkdir -p .claude/agents mkdir -p docs/markdown mkdir -p docs/markdown_mermaid/{images,mermaid} mkdir -p docs/{pdf,word}步骤 3:定义你的 Agents
在 .claude/agents/ 目录中为每位专家创建 Markdown 文件,指令务必明确、具体。复制我在 GitHub 上的模板作为起点。
步骤 4:运行 Orchestra
告诉 Claude Code:"使用 workflow-orchestrator 处理所有 Markdown 文件"
接着看魔法上演。
前沿的启示
与这套系统共事的经历,让我深刻体会到软件开发的未来方向。
亮眼之处
关注点分离让调试变得轻而易举
自然语言指令消除了学习曲线
优雅的错误处理防止了流程中断
清晰的文件组织让输出易于查找
首次尝试成功证明了该方法的鲁棒性
出乎意料的发现
智能体的表现比传统脚本更可靠
我团队中的非程序员也可以修改代理行为
该系统通过对话而非编码得以改进
复杂的工作流程变得出奇地易于管理
错误恢复无需干预即可自动完成
未来增强
有了这些基础,我可以轻松添加:
多文档的并行处理
不同类型的图表(PlantUML、GraphViz)
自定义 PDF 样式与模板
自动化质量检查
与 CI/CD 流水线的集成
实时监控进度
范式变革已经到来
我们正在见证软件开发方式的根本性转变:不再是偶尔调用 AI 的代码编写,而是编排偶尔执行代码的 AI 代理。
取代程序员并非目的;真正的意义在于让自动化民主化。业务分析师、内容创作者、研究人员和教育工作者如今无需编写一行代码,即可构建复杂的工作流。
自动化的门槛已经从“多年编程经验”转向了“用自然语言清晰表达意图”。这开启了种种我们可能才刚刚开始探索的可能性。
你的下一步
安装 Claude Code,探索其智能体系统
复制我的实现 ,GitHub 获取(链接见简介)
用智能体思考 :把复杂任务拆分成专业角色
分享你的作品 :社区正在打造令人惊叹的解决方案
从小处着手。挑一个你手动的重复性任务。创建2–3个智能体来自动化它。体验看着智能体协作解决问题的奇妙感。
结论
我只用了几分钟配置代理,就替代了原本需要数天甚至一周的传统开发。最终得到的系统比我亲手写的任何代码都更易维护、更灵活、也更易读;写这篇文章花的时间,比我搭建所描述的代理子系统还要久。
七个代理证明,复杂的技术工作流完全可以用自然语言编排实现。无需编码,无需调试,只需清晰的指令和智能协作。
自动化的未来不仅在于写出更好的代码,更在于编排更智能的代理。而这样的未来,如今通过 Claude Code 即可触手可及。
最令人惊讶的是,整条管道首次运行就完美无误:没有调试、没有配置微调、没有 Stack Overflow 搜索,仅凭自然语言就转化为一套可直接投产的系统。
运行时较慢,但结果令人印象深刻。我很期待这套系统在面对更大规模项目时会有怎样的表现。我们可以将代理的部分任务改用 Python 编写,例如 UTF-8 清理、提取 Mermaid 图表以及图像生成等,从而提升速度。这样代理会更高效;若 Python 脚本无法运行,仍可退回到目前的代理处理方式(或者让代理自行修复代码)。
改进领域
有一个可以改进的地方是运行速度。系统比传统工具明显慢得多。虽然我写过或用过不少执行飞快的同类工具,但 LLM 的处理时间还是让速度比专门设计的软件慢了一拍。不过取舍很明显:速度上的损失换来了更强的适应性和错误处理能力。
或许值得尝试一种混合方案:先生成处理日常工作的代码,当遇到错误时再让智能体去修改这些代码,从而构建一个能在更高速度下运行的自愈系统。这个想法在我脑海里酝酿已久了。
我发现这一范式极其强大。在 Claude Code 中大量使用子智能体之后,无论是通过命令行还是子智能体,用自然语言就能描述复杂操作,简直是一场革命。我因此做出了一些原本没时间开发的工具——用于数据分析、在遗留政府数据集里进行复杂搜索等等。
其适应性尤为出色。有一次在扫描政府网站记录时,CSV 文件格式因年代更迭发生变化,子代理们仍能自行适应并解决。我相信,这种“神奇”软件与传统代码的关键区别正在于这种即时调整能力。我们付出的代价是更长的处理时间,但这就是当下的现实。
随着 LLMs 变得更快、更智能,性能差距可能会逐渐缩小。这些让我夜不能寐;在這種新编程范式的种种可能中思索与徘徊。
暂无评论
发表评论